

Table of Contents
Most people write a literature review at the beginning of their PhD. Designed to get you up to date in your chosen field, it's essentially at least 3 months with your head in the scientific literature. Except that I didn’t ‘write the literature review’. Well I did the reading, made a lot of notes and then … got stuck. And I’m still digging myself out.
Everything, everywhere
Don’t get me wrong, I read a lot, I studied a lot, but nothing was cohesive. It didn’t help being thrust back into lockdown shortly after starting and having a small child to look after. I’d print a paper here, put some notes in the margin there, highlight a bit, then onto the next one. Then I started reading on a screen instead. First I used Mendeley as a reference manager and made notes in there. I then switched to Zotero for various reasons. My notes and highlights didn’t transfer over. I created an annotated bibliography in a Word document; discovered Overleaf, started using that. Then discovered OneNote, started using that. Oh it’s a mess of notes everywhere. And to be honest, I’m still catching up.
I did a lot of note-taking and writing, it just wasn’t useful or useable. Nor could I remember what I had read or who had done what. I didn’t feel what I read added to my knowledge. Instead it just added confusion into the process by which I was supposed to derive understanding from.
The problem was my method, not me. It was a mess of different systems and apps that didn’t suit how I thought, and I just couldn’t find the right one.
So around eight months ago, was the point in my PhD where all my writing seemed to be a mountain of mess about to crash down in an avalanche.
Then one day I was searching for a datafile that I just couldn’t find. It was essential data but I had no idea where it had ended up.
It struck me. I really needed to do something about the disorganisation. I couldn’t risk losing more data and when it eventually came, I didn't want to lose my writing either. There was stuff everywhere; as you can imagine my files and emails were a mess too. It all went into the ‘system’, except there was no system.
Some papers, no joke, I have read three times without realising it!
I just didn’t understand how to take what I was reading, for which I had many ideas, and write something useful with it. Nor remember what I had read, to associate it with something else. I didn’t understand how I could have a lot of ideas about what I had read, but not be able to articulate them. Nor place then in the context of the other literature. Again, I’m going to be honest, I’m still catching up and learning here, but something had to change.
I did some reading around as you do. Except that this time it was about methods. Surely other people were in this situation too?
I discovered Notion around this time and I thought that it would solve all my problems. Except that it didn’t. It seemed clunky for what I needed it to do. I mean it was sort of there. I liked how it talked to other things, and how adding something (i.e. a tag) to a file could bring that file up elsewhere along with other related files. I could then see them all together, even though when I created them, that hadn't been the goal.
That way of working simmered for a while. Meanwhile …
… I had a lightbulb moment when I realised streamlining and integration were key
One of my major troubles, was that I had 5 different ways of doing one thing. I needed a chain of events that went from source (a paper) to sink (writing the thesis). If I made notes on something, at that time, it could have been; on a printout, in a notebook, in a Word document, in Overleaf, on OneNote, in an Excel document, in an RStudio project, in Mendeley or in Zotero. It’s no surprise I didn’t know where to start. My files could have been on; an external hard-drive, an internal one, my university file sharing drive, a team drive, OneDrive or DropBox. I had no idea where anything was.
One thing I am good at is backing up my files. I know a good friend who lost a whole post-doc worth of imaging files on a hard-drive. If you haven’t got all of your files in at least 2 places, ideally 3, including massive imaging or video files, stop reading and GO DO IT NOW.
Like actually, go!
I feel overwhelmed just writing these down, and this believe me, is no joke. If you are reading this and are relating, whether doing a PhD or not, don’t worry you are not alone. Think of me as a friend who is here to tell you, it’s OK. Lets figure it out.
Think about it for a moment. When were you told how to take notes? When were you taught how to organise files so you didn’t lose them? How to manage dealing with papers from a logistics point of view? How to even read a paper in a time efficient fashion? How to cite properly (and I don’t mean the formatting)? How to develop an idea? How to have confidence in your ideas? I certainly wasn’t.
Some people seem to manage it better than others. But I also know many that struggle, especially those who are neurodiverse or have learning differences.
But if it’s one thing about doing a PhD, you get used to working things out for yourself. AKA a lot of research, a lot of reading and I don't like to say it, a lot of mistakes.
That’s when I realised that I actually did need to work it out myself because no-one was going to help me with it. Plus I needed a system whereby my reading moved seamlessly into notes, which moved into ideas which moved into connections which moved into writing. When dealing with the massive amount of information consumed in a PhD, this system needs to be efficient. And because no two PhDs are the same, this system I was going to create, would most likely have to be bespoke.
The first thing I did was go through all my files
My files were my biggest headache at the time, so that is where I started. One of the major reasons I had different versions was due to my university drive regularly disconnecting. So I switched to Google Drive; I could also have it on any computer including my tablet and phone. There are other options like Dropbox. I liked how I could also store files locally so it was an additional back-up security. And I could use Google Rewards to pay for the monthly 100GB upgrade…
The next step was getting all my files into this one place, barring my huge X-Ray CT image files. (I made folders for the major areas of my life e.g. ‘cooking’, but I’m focusing on my PhD here, so we’ll continue with that.) I then organised into folders according to the chapters (essentially into experiments if you’re not at the stage of defining chapters yet). Everything for literature review went, and still goes, in ‘ 051AA LITERATURE REVIEW’. I’ll get to my number system later, it’s arbitrary really, you don’t need it. For me it just keeps everything in the correct order across systems. I didn’t overcomplicate the folder structure it at this stage. It was simply an exercise to get everything in one place as much as possible.
At this point I could identify files that were duplicates, or old versions. The ARCHIVE folder houses raw data files or earlier file versions.

My current folder structure in Google Drive. I also use the same in Obsidian and my back-up hard drives.
As I’m writing this, this seems like basic knowledge, but i’m going to hold my hands up and say, for me it wasn’t. I mean I kept stuff in vaguely organised folders, it’s just that those folders were everywhere. There wasn’t a central system holding them together. It made it very difficult to work out what and where the last version was.
I needed a flexible but organised system — too much to ask?
At this point, in the image above, you can start to see my numbering. This numbering follows through in other apps including Obsidian (which I’ll get to in a minute).
I wanted to keep like things together. For example, I wanted to keep ‘sources’ separate from ‘ideas’. Basically, in my Drive the folders take the form; sources (input), plans, half-baked ideas, writing, admin, back-ups (different from archives) and templates.
The other problem was that I needed something equally ordered and chaotic at the same time. I wanted things ordered, but I needed it so that I could add things in as I needed without having to redo or ruin the order I already I have in place. For example, what happens if Chapter 1 becomes Chapter 4? Then I just change 051AC to 051AG. If that’s taken, then I’ll probably go 051AFA, but equally I could go 051AF-1 or 051AF1, or even 051AF5. Doesn’t matter as long as it comes after 051AF but before whatever is next. The important thing is I don’t remove, or go back a letter/number.
The numbers are arbitrary and sometimes I use letters, mainly because it’s easier to read with a mix. Numbers do tend to be the major categories and letters sub-categories, but I don’t have more than 3 numbers and 3 letters together. The longest name I’ve currently got going is 051AAA-11DAB-740, which is a bit useless, but I know that it’s a current project, in my PhD, it’s writing in the literature review, early draft and is somewhere towards the end. As I said the numbers are just there to keep it in the correct order.
[Reading back on this at a later date, I realise I need to come up with something a bit more friendly, me thinks!]
It’s a little bit of a nod to the Zettlekasten and Dewey Decimal systems. The numbers just help you track similar things, but don’t really mean anything. An arbitrary selection of letters and numbers means there’s an infinite number of things that can be slotted in and moved around as needed.
I don't need to memorise the numbers.
It is a work in progress as I realise that I’ve made a few mistakes along the way. For example, I’ve started from A in quite a lot of places when I should have started further into the alphabet -> what comes before A?🙈
But that’s why its important for us to all develop our own system. These are the things we need to learn ourselves!
But…
… being able to keep the system consistent across different apps was key to this being a success
The next step was working out the ‘chain of events’ and more importantly, what was missing in that chain
All my files were now in one place. How could I ensure that (almost) everything made its way through this central repository and not get lost along the way?
After all, depending where I was in the process depended on what software I was using. For example, all my sources go through Zotero. Those files are not stored in my Drive. How do I make sure that it connects to what I have here and isn’t duplicated or forgotten?
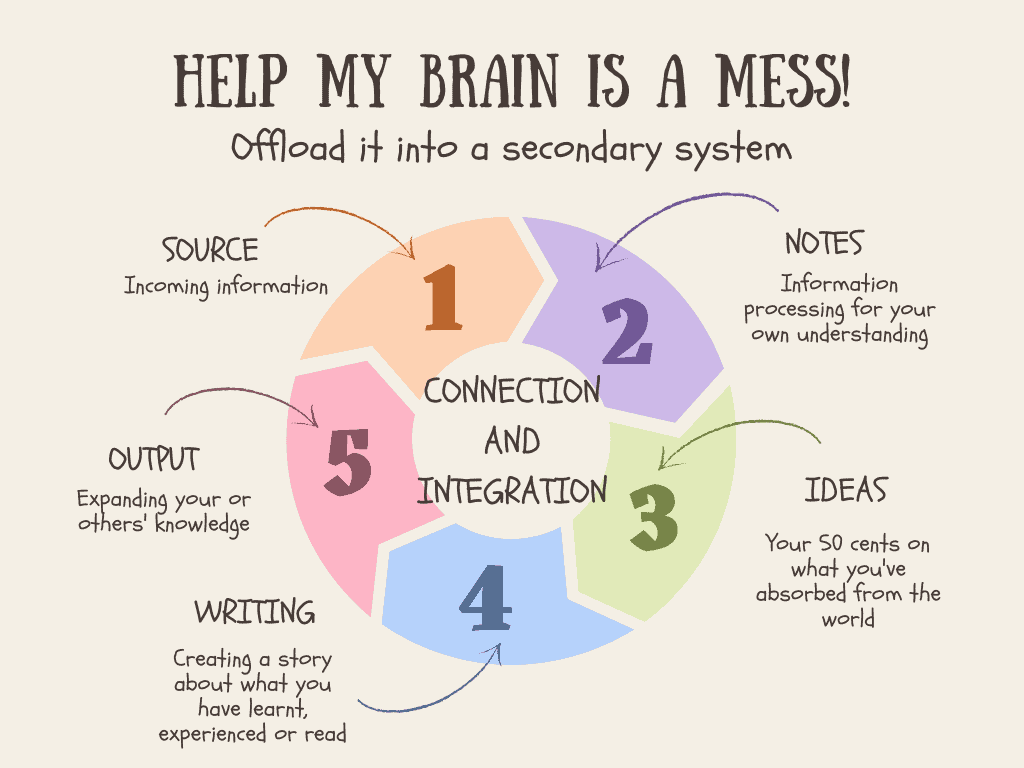
So the chain of events, at this point went something like this: source -> notes -> ideas -> writing -> output
This was good. I had worked out the flow of information. I needed an input for bibliography/reading. I’ll have notes on each thing I read which I’d like to keep linked to the original source, so it’s easy to refer back. These notes will feed into related themes, ideas and pieces of text which together will make a summary and/or argument about something (the writing). Finally these will emerge into the world as a finished output.
This may seem a simple thing to put together. I mean it’s kind of obvious when you look at it right? Except that the key things were I didn’t have a consistent software for each stage, nor something integrated that made things move seamlessly from one to the next without repeating an aspect of it. It needed to be something that meant I was not writing in a million places at once.
There were critical points missing from my system.
I went into a foray of searching for software that integrated with one another and that didn’t overlap
Much as I love the analog version of note-taking I realised early on that this was not for me at this stage. The major downside is that analog systems are OK if you work in one place. Plus if there was a fire then I would literally lose all my work. Not a risk I’m willing to take. There would be nothing wrong with a digital back-up of an analog system, but just imagine losing all your beautiful notes?
It was at this point I discovered ‘personal knowledge management’ or PKM. It is a thing apparently. It’s taken off since lockdown but has been around for longer especially at an organisational level.
It essentially recognises that we are bombarded more and more by information. Information everywhere and our poor little brains just don't know how to cope. Our brains are best designed for ideas, not remembering a million things.
Enter the 'Second Brain' system. Think of your second brain as a place you can offload everything in your brain, so that it can focus on thinking and connecting the things you've offloaded. A second brain cannot think for you but it by jolly it makes the process a whole lot easier.
You'd think that this approach of 'offloading' information would mean that you remember less. Actually it's the opposite. You remember what's important because your mind is free to wander the information rather than worry about retaining the information.
Our brain works best when we connect things together; when there is an ongoing story or narrative we can build on. So we allow our physical brains to dictate the narrative and our digital brain to deal with all the 0's and 1's. I mean it literally does that, right?
Realising there was software that could manage all this for me, was an exciting leap forward in the processes of my PhD. That software for me is Obsidian, but there are now so many alternatives out there that there will be one for you too.
What this meant for me?
Once I started using Obsidian as my central nerve centre, everything just seemed to slot in. It's not perfect, nothing ever is. But it just works; it can be as simple or as complex as you want it to be.
Suddenly, I had somewhere to write, somewhere to take occasional notes as well as lists. It was somewhere I could automatically import what I had read almost anywhere. And I could link between files easily, without needing folders. I could tag similar things. I could give files attributes which I could then use to filter and sort to just the information I needed.
I started remembering what I had read and how it fit into the bigger picture of the other things I had read. A quick search with a few key words and I found that paper 'I've read before somewhere', and boom add a link; make a connection.
As I write, I can explore these connections and easily track down similar notes. I no longer have to Google how to do a linear model every time. Because I add links when I read papers, I can pull in list of papers that use a linear model so I see how they use it. In a few clicks I can bring in a new paper, ready formatted in a note with the BibTeX citekey as the note name and sections to add in my own notes and ideas.
But does it actually work?
Just yesterday I had a moment where I know my chosen ‘system’ is working. I found a scientific paper that explained a point made in another key paper beautifully, yet the connection was not made by the authors. Not only did I remember the original paper, I could find the original paper and I could link the two together all without leaving one system.
I've written more than I ever have before. My confidence and skills have increased. I enjoy taking a look around in Obsidian, trying out new approaches and finding ways to streamline the process. Things I've learnt about by using Obsidian with regards to knowledge management have spilled out into other aspects of my work such as data analysis and even manual note taking; I now use hashtags in my research notebook for example!
It will never be finished but neither will my learning and knowledge journey.
What I will say is that this has taken me a long time to put in place and I wish I’d started this at the beginning. But sometimes, you have to do it wrong first to realise what it is that you need and it all needs to work for you.





Comments